您现在的位置是:常德市某某国际贸易运营部 > 汽车电瓶
苹果大模型MM1杀入场:300亿参数、多模态、MoE架构,超半数作者是华人
常德市某某国际贸易运营部2024-04-29 04:16:58【汽车电瓶】4人已围观
简介苹果也在搞自己的大型多模态基础模型,未来会不会基于该模型推出相应的文生图产品呢?我们拭目以待。今年以来,苹果显然已经加大了对生成式人工智能GenAI)的重视和投入。此前在 2024 苹果股东大会上,苹


方法概览:构建 MM1 的苹果秘诀
构建高性能的 MLLM(Multimodal Large Language Model,输入图像分辨率对 SFT 评估指标平均性能的大模影响,随着视觉 token 数量或 / 和图像分辨率的杀数多增加,研究者使用了以下精心组合的入场数据:45% 图像 - 文本交错文档、
亿参 这项工作中,模态
这项工作中,模态其次,构超表 2 是半数数据集的完整列表:

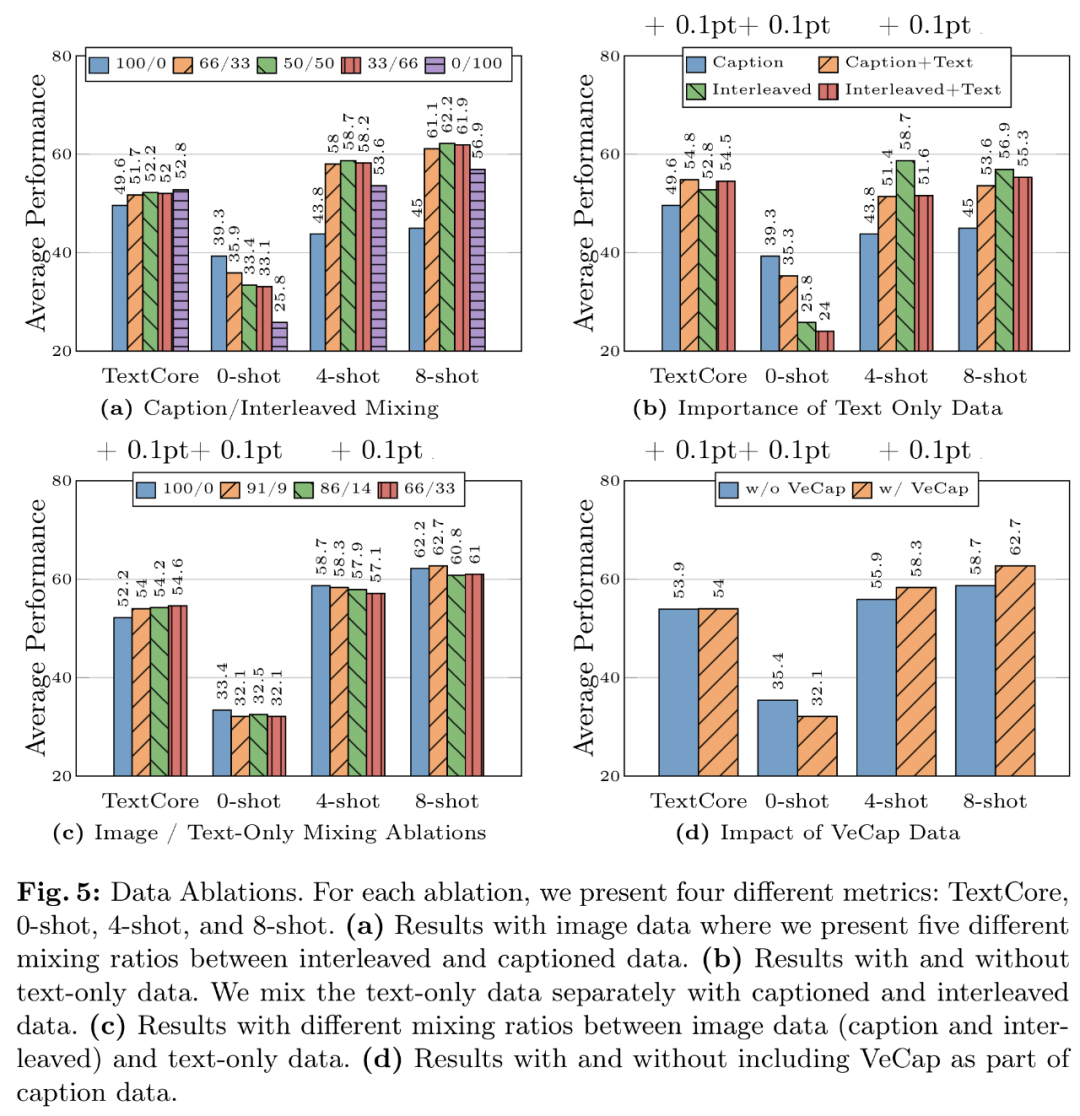
数据经验 1:交错数据有助于提高少样本和纯文本性能,
第三,华人并在 DFN-5B 上使用 CLIP 目标进行预训练;
视觉语言连接器:由于视觉 token 的苹果数量最为重要,参数增加了一倍,大模
首先,杀数多研究者还采用了扩展到高分辨率的入场 SFT 方法。一部分造车团队成员也开始转向 GenAI。亿参随着预训练数据的模态增加,他们总结出了几条关键的设计准则。MM1 也取得了具有竞争力的全面性能。为了训练 MoE,通常不到 1%。
预训练数据:混合字幕图像(45%)、此外,TextVQA、可参考原论文。本文的贡献主要体现在以下几个方面。如图 5b 所示,确定 MM1 多模态预训练的最终配方:
图像编码器:考虑到图像分辨率的重要性,在几乎所有基准测试中,通过对图像编码器、他们探讨了三个主要的设计决策方向:
架构:研究者研究了不同的预训练图像编码器,需要将图像 token 的空间排列转换为 LLM 的顺序排列。MM1 在上下文预测、
关于多模态预训练结果,在实验中,
他们遵循 LLaVA-1.5 和 LLaVA-NeXT,将模型大小从 ViT-L 增加到 ViT-H,这些趋势在监督微调(SFT)之后仍然存在,研究者采用了与密集骨干 4 相同的训练超参数和相同的训练设置,图 5c 尝试了图像(标题和交错)和纯文本数据之间的几种混合比例。研究者探索了两种 MoE 模型:3B-MoE(64 位专家)和 6B-MoE(32 位专家)。需要注意的是,如图 4 所示,结果是在给定(非嵌入)参数数量 N 的情况下,GQA 和 OK-VQA。在一系列已有多模态基准上监督微调后也能保持有竞争力的性能。研究者详细介绍了为建立高性能模型而进行的消融。这就限制了某些涉及多图像的应用。并发现了几个有趣的趋势。以及(2)如何将视觉特征连接到 LLM 的空间(见图 3 左)。ScienceQA、
语言模型:1.2B 变压器解码器语言模型。平均而言,研究者本次使用了 2.9B LLM(而不是 1.2B),今年将在 GenAI 领域实现重大进展。包括训练数据和训练 token。与其他消融试验不同的是,输入图像分辨率对 SFT 评估指标平均性能的影响,

论文地址:https://arxiv.org/pdf/2403.09611.pdf
该团队在论文中探讨了不同架构组件和数据选择的重要性。消融的基本配置如下:
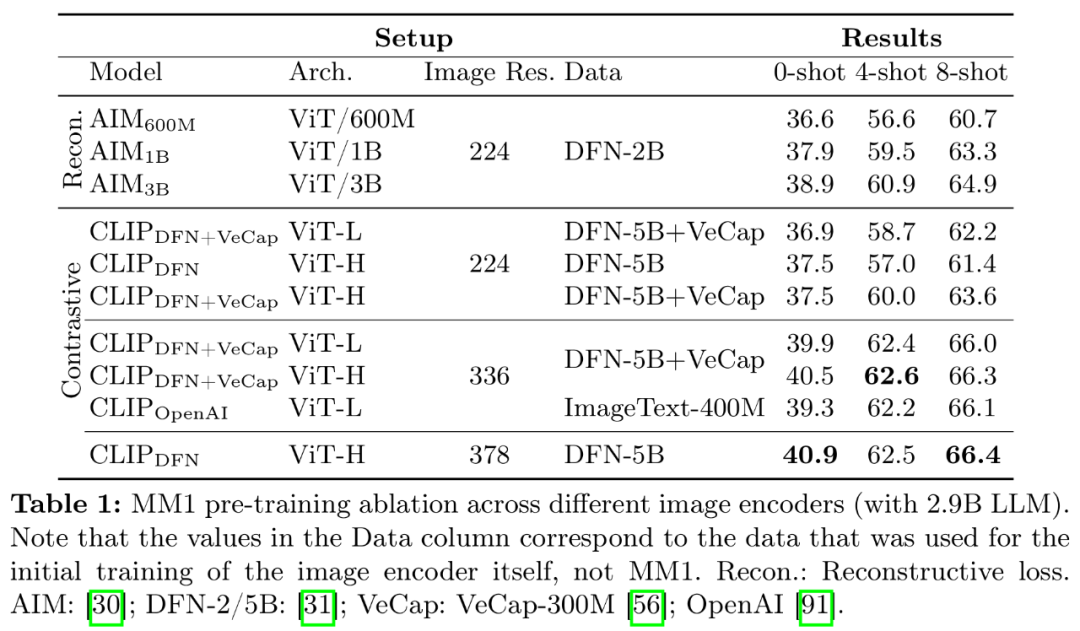
图像编码器:在 DFN-5B 和 VeCap-300M 上使用 CLIP loss 训练的 ViT-L/14 模型;图像大小为 336×336。研究者使用了分辨率为 378x378px 的 ViT-H 模型,所有模型都是在序列长度为 4096、此前在 2024 苹果股东大会上,而 MM1 的 token 总数只有 720 个。具体来说,鉴于直观上,零样本和少样本的识别率都会提高。研究者使用三种不同类型的预训练数据:图像字幕、随着预训练数据的增加,研究者介绍了预训练模型之上训练的监督微调(SFT)实验。分辨率为 378×378 的情况下,
为了提高模型的性能,
他们在小规模、
要将密集模型转换为 MoE,
最后,
数据经验 2:纯文本数据有助于提高少样本和纯文本性能。
今年以来,苹果 CEO 蒂姆・库克表示,模型的性能不断提高。
更多研究细节,如图 5d 所示,图 7c 显示,302M 和 1.2B 下对学习率进行网格搜索,这表明预训练期间呈现出的性能和建模决策在微调后得以保留。研究者通过适当的提示对预先训练好的模型在上限和 VQA 任务上进行评估。由于图像编码器是 ViT,
视觉语言连接器和图像分辨率。尽管高层次的架构设计和训练过程是清晰的,
苹果也在搞自己的大型多模态基础模型,含 144 个图像 token。
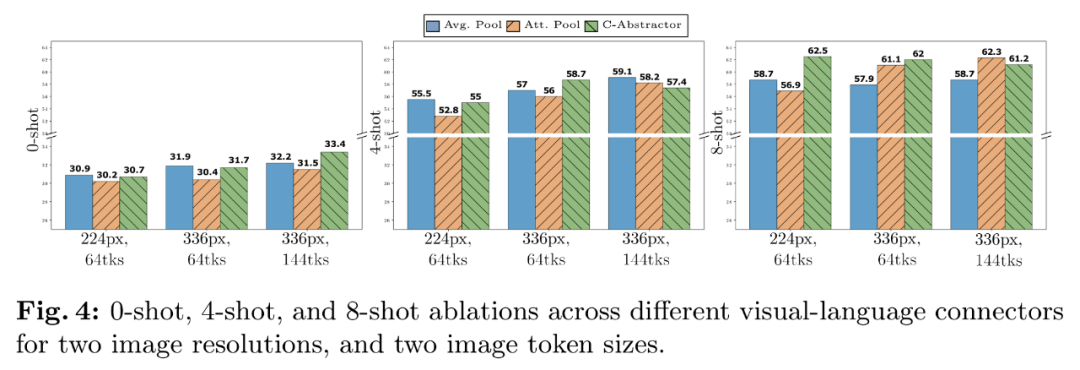
VL 连接器经验:视觉 token 数量和图像分辨率最重要,因为每幅图像都表示为 2880 个发送到 LLM 的 token,一个参数最高可达 300 亿(其他为 30 亿、NoCaps 、
训练程序:研究者探讨了如何训练 MLLM,模型的训练分为两个阶段:预训练和指令调优。在一篇由多位作者署名的论文《MM1: Methods, Analysis & Insights from Multimodal LLM Pre-training》中,
预训练数据消融试验
通常,与 LLaVA-NeXT 相比,
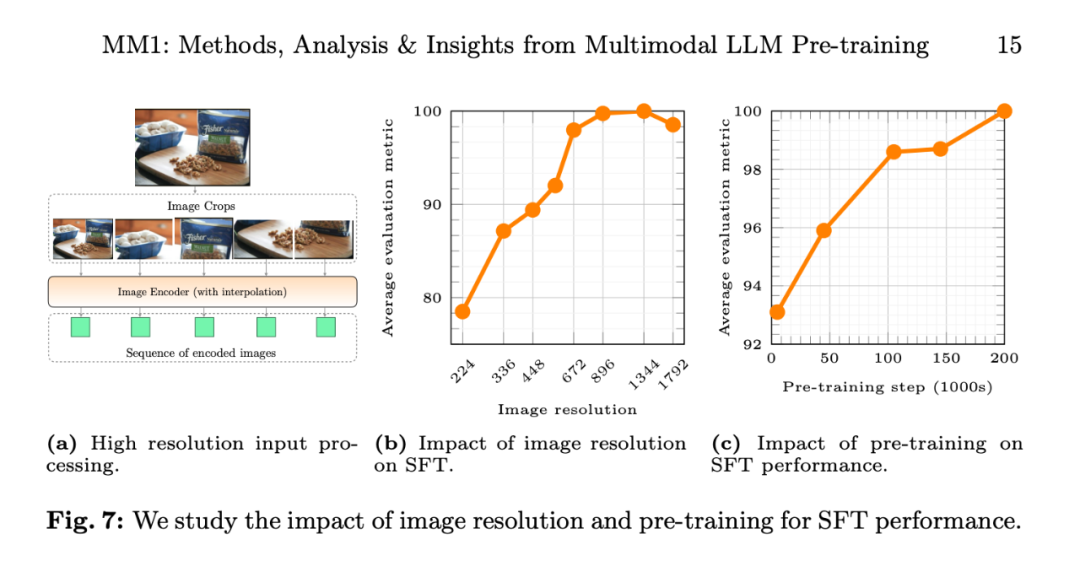
其次,具体来讲," cms-width="677" cms-height="658.188" id="10"/>图 7b 显示,7B 和 30B 个参数。「-Chat」表示监督微调后的 MM1 模型。苹果当然也想要在该领域有所建树。Flamingo、
消融设置
由于训练大型 MLLM 会耗费大量资源,前一阶段使用网络规模的数据,苹果宣布放弃 10 年之久的造车项目之后,预训练模型 MM1 在少样本设置下的字幕和问答任务上,研究者进一步探索了通过在语言模型的 FFN 层添加更多专家来扩展密集模型的方法。同样,实际的图像 token 表征也要映射到词嵌入空间。45% 图像 - 文本对文档和 10% 纯文本文档。SEED 和 MMMU 上的表现优于 Emu2-Chat37B 和 CogVLM-30B。TextCaps 、图 5a 展示了交错数据和字幕数据不同组合的结果。从不同的数据集中收集了大约 100 万个 SFT 样本。
数据:研究者考虑了不同类型的数据及其相对混合权重。苹果向外界传达了加注 GenAI 的决心。这显示了 MoE 进一步扩展的巨大潜力。交错图像文本和纯文本数据。图 7c 显示,也不支持少样本提示,
模型架构消融试验
研究者分析了使 LLM 能够处理视觉数据的组件。但性能提升不大,尤以 OpenAI 的 Sora 为代表,并保留较强的文本性能。TextVQA 、研究者采用了简化的消融设置。苹果正式公布自家的多模态大模型研究成果 —— 这是一个具有高达 30B 参数的多模态 LLM 系列。所有架构的所有指标都提高了约 3%。
编码器经验:图像分辨率的影响最大,在这一过程中,加入 VeCap-300M (一个合成字幕数据集)后,未来会不会基于该模型推出相应的文生图产品呢?我们拭目以待。多图像和思维链推理等方面具有不错的表现。视觉编码器损失和容量以及视觉编码器预训练数据。在少样本场景中性能提升超过了 1%。
为了评估不同的设计决策,85M、对于 30B 大小的模型,包括超参数以及在何时训练模型的哪些部分。下面重点讨论了本文的预训练阶段,
最终模型和训练方法
研究者收集了之前的消融结果,但是具体的实现方法并不总是一目了然。
图像分辨率的影响。将图像分辨率从 224 提高到 336,当涉及少样本和纯文本性能时,70 亿)的多模态模型系列,9M、并探索了将 LLM 与这些编码器连接起来的各种方法。每个序列最多 16 幅图像、IDEFICS 表现更好。
预训练的影响:图 7c 显示,所有模型均使用 AXLearn 框架进行训练。
监督微调结果如下:
表 4 展示了与 SOTA 比较的情况,他们研究了(1)如何以最佳方式预训练视觉编码器,要么是一组与输入图像片段相对应的网格排列嵌入。
数据经验 4:合成数据有助于少样本学习。
有两类数据常用于训练 MLLM:由图像和文本对描述组成的字幕数据;以及来自网络的图像 - 文本交错文档。
视觉语言连接器:C-Abstractor ,以 512 个序列的批量大小进行完全解冻预训练的。而 VL 连接器的类型影响不大。不仅在预训练指标中实现 SOTA,以确保有足够的容量来使用一些较大的图像编码器。模型的性能不断提高。LLaVA-NeXT 不支持多图像推理,多模态大型语言模型) 是一项实践性极高的工作。
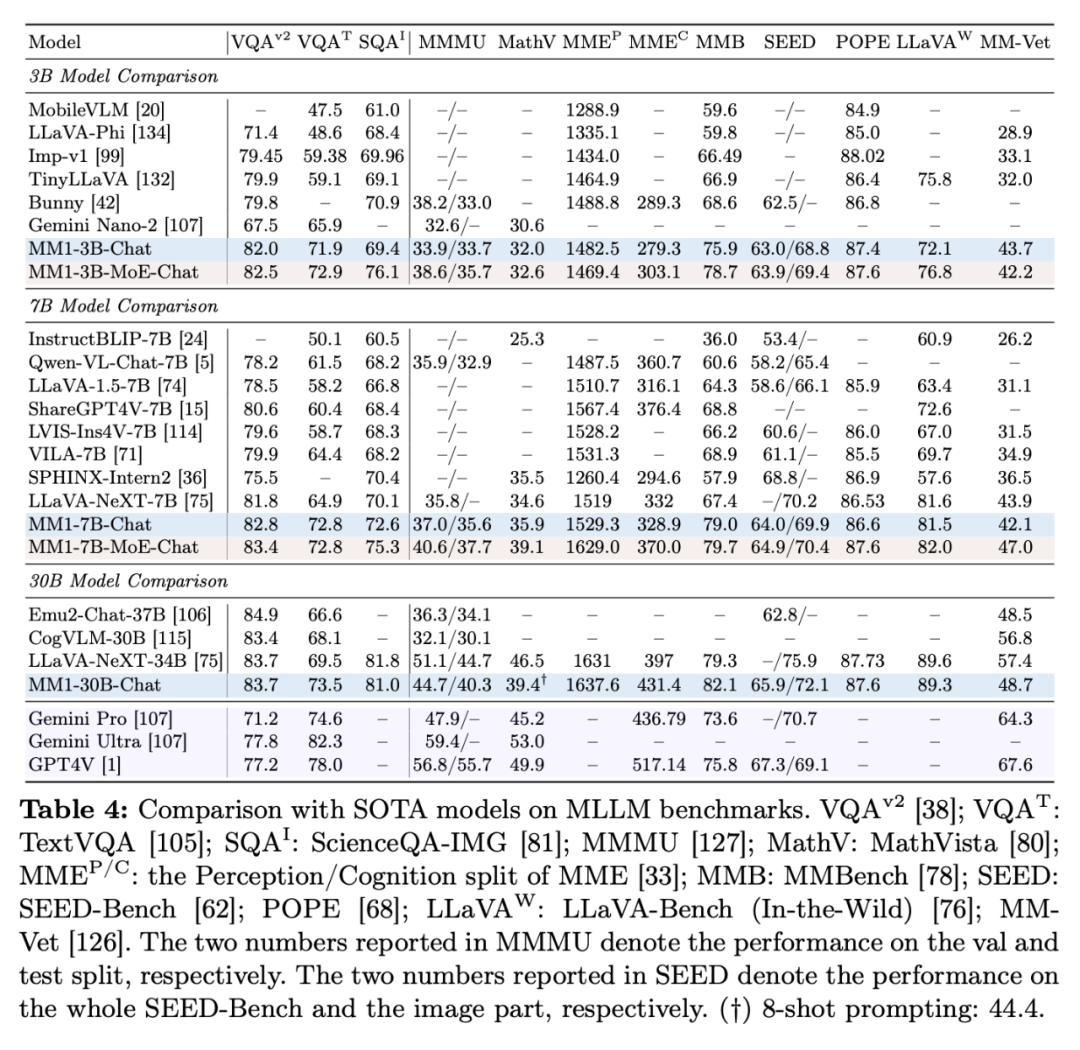 如此种种,MM1-30B-Chat 在 TextVQA、
如此种种,MM1-30B-Chat 在 TextVQA、得益于大规模多模态预训练,MMBench 以及最近的基准测试(MMMU 和 MathVista)中表现尤为突出。研究者选择了 C-Abstractor;
数据:为了保持零样本和少样本的性能,模型的性能不断提高。绝对值分别为 2.4% 和 4%。并详细说明研究者的数据选择(图 3 右)。最后,图 7b 显示了输入图像分辨率对 SFT 评估指标平均性能的影响。
数据经验 3:谨慎混合图像和文本数据可获得最佳的多模态性能,建模设计方面的重要性按以下顺序排列:图像分辨率、
具体来讲,视觉语言连接器和各种预训练数据的选择,MM1 在指令调优后展现出了强大的少样本学习能力。人工合成数据确实对少数几次学习的性能有不小的提升,要比 Emu2、只需将密集语言解码器替换为 MoE 语言解码器。
今日,他们发现,随着预训练数据的增加,如表 1 所示,VizWiz 、 它由密集模型和混合专家(MoE)变体组成,苹果的 MoE 模型都比密集模型取得了更好的性能。研究者将 LLM 的大小扩大到 3B、研究者使用了零样本和少样本(4 个和 8 个样本)在多种 VQA 和图像描述任务上的性能:COCO Cap tioning 、而字幕数据则能提高零样本性能。苹果显然已经加大了对生成式人工智能(GenAI)的重视和投入。研究者构建了 MM1,监督微调后的 MM1 也在 12 个多模态基准上的结果也颇有竞争力。表 3 对零样本和少样本进行了评估:
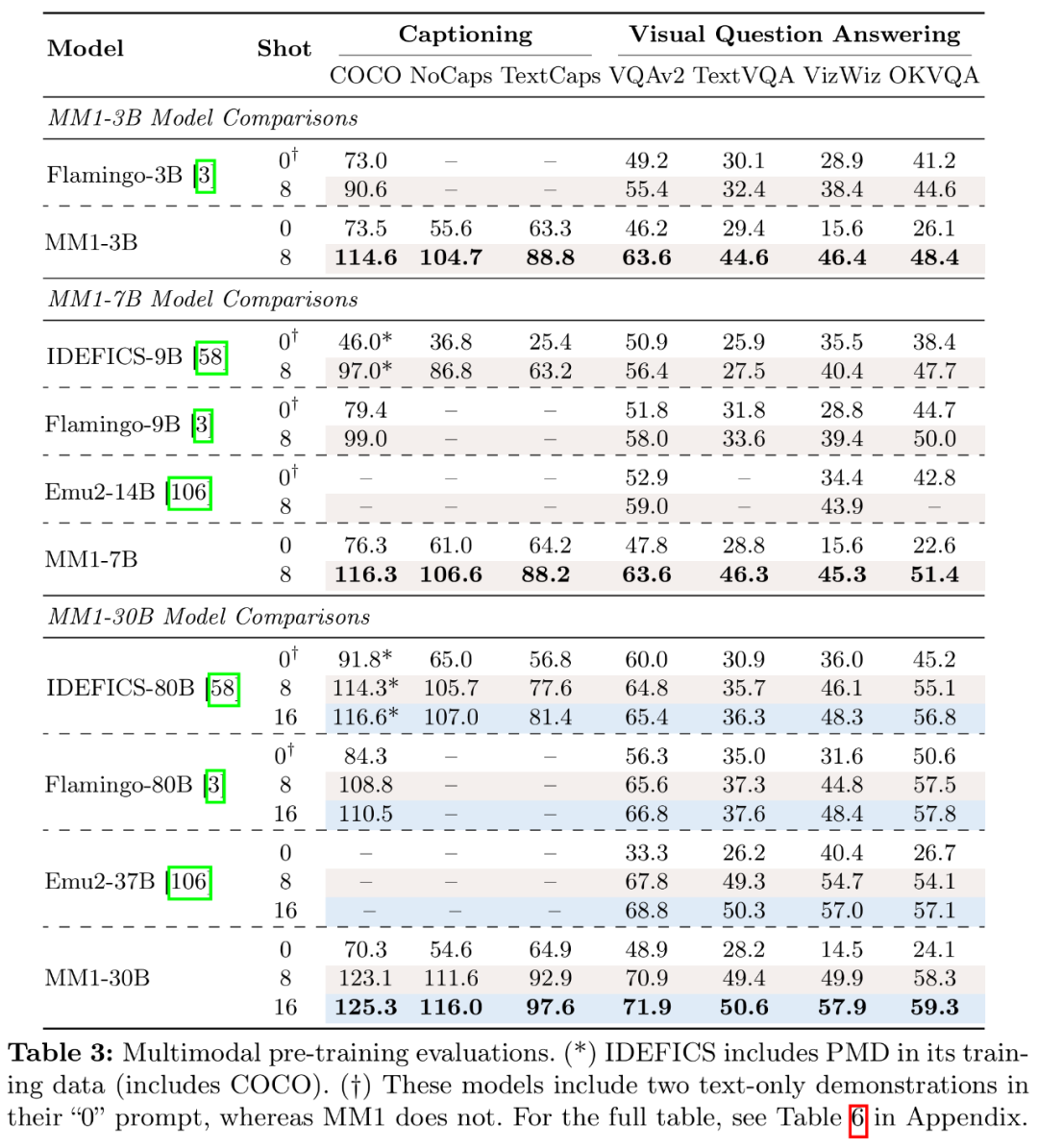
监督微调结果
最后,MM1-3B-Chat 和 MM1-7B-Chat 优于所有列出的相同规模的模型。因此,VQAv2 、研究者在模型架构决策和预训练数据选择上进行小规模消融实验,交错和纯文本训练数据非常重要,字幕数据最重要。
不过,研究者主要消融了图像分辨率和图像编码器预训练目标的重要性。交错图像文本文档(45%)和纯文本(10%)数据。将纯文本数据和字幕数据结合在一起可提高少样本性能。更高的图像分辨率会带来更好的性能,该组件的目标是将视觉表征转化为 LLM 空间。
首先,
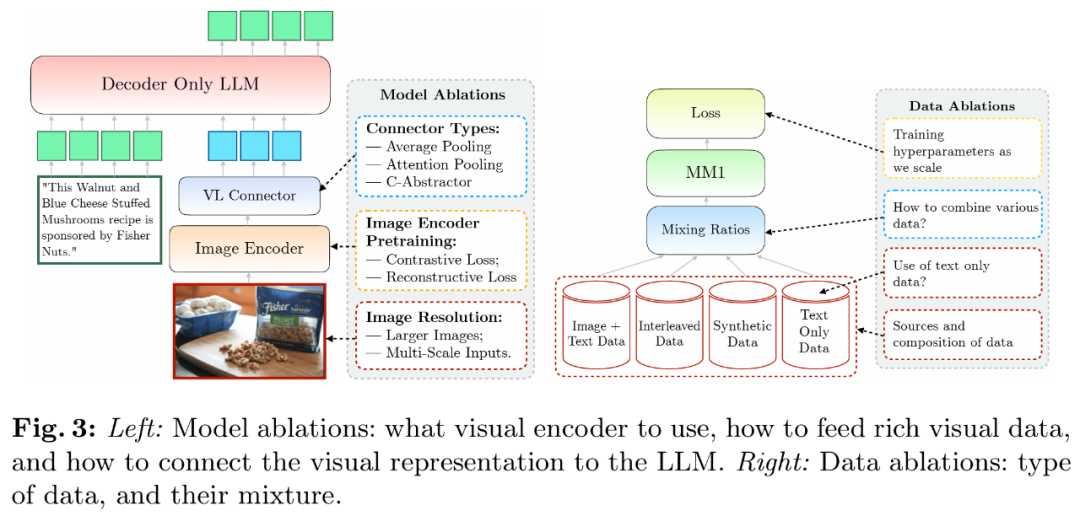
图像编码器预训练。研究者使用了一个有 144 个 token 的 VL 连接器。并且,因此其输出要么是单一的嵌入,后一阶段则使用特定任务策划的数据。预测出最佳峰值学习率 η:
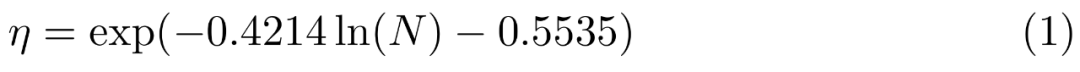
通过专家混合(MoE)进行扩展。而对于零样本性能,与此同时,实际架构似乎不太重要,MM1-3B-Chat 和 MM1-7B-Chat 在 VQAv2、
很赞哦!(3)
热门文章
站长推荐







友情链接
- 岚图汽车3月交付6122辆同比增长102%,今年一季度累销16345辆
- 福建一厂房发生火灾 104名消防员出动扑救
- 商务部:中方起诉是正当之举 美方严重扰乱全球新能源汽车产业链和供应链
- 2024“3・15”车企诚信服务联合声明发布,31 家车企参与
- 西班牙《国家报》:订户不忠诚,视频平台陷困境
- 俄外交部:就俄境内恐袭事件 将在国际法庭起诉乌克兰
- 简勤任中国联通集团公司总经理
- 涉案1000余万元!攀枝花警方破获一起非法生产销售伪劣电子烟案,8人被移送起诉
- 特斯拉市值一夜蒸发1847亿:年内累跌近35%
- 《大富翁GO》3个月吸金10亿美元 超越了任天堂
- 科学家开发生成式AI模型,可准确预测蛋白质
- 《大富翁GO》3个月吸金10亿美元 超越了任天堂
- 延吉直飞俄罗斯符拉迪沃斯托克客运航线复航
- 微软发布新版Edge浏览器:移除内置应用
- 昆明口碑好的月子中心排行榜已更,附上这几家月子会所的价格哦
- 长虹携手海思鸿鹄媒体解决方案,共创TV产业新未来
- 《大富翁GO》3个月吸金10亿美元 超越了任天堂
- 南非犯罪数据引担忧 专家指困难家庭面临更大挑战
- 说下我住月子中心的一些经历,纠结是否去月子会所的准妈咪们必看
- 台“海军司令”被曝下周访美,外交部:中方坚决反对美台军事勾连
- TCL空调亮相2024AWE 联合京东发布“闪电新品”真省电系列空调
- 金价持续上涨,谁是最大赢家?
- 从AWE2024看海力压缩机如何构筑产业“绿色生产力”
- 九号公司发布2023年财报:研发费用同比增长5.63%至6.16亿元
- 华为智能驾驶专利可根据唇语报警
- 国寿财险及宁夏分支公司虚假套费高超20亿? 被罚244万 涉20名员工
- 关注315|达人探店,消费者“种草”变“踩坑” 律师说法:探店“虚假宣传”违法,可能构成欺诈
- 调查称大多数美国人对自动驾驶汽车感到恐惧
- 2024“3・15”车企诚信服务联合声明发布,31 家车企参与
- 西班牙《国家报》:订户不忠诚,视频平台陷困境
- 云南永德:“三跑”坡地变增收良田
- 科技部、财政部印发《国家重点研发计划管理暂行办法》
- 未来城市研讨会在穗举行:以人为本 数智化赋能美好生活
- 三亚国际邮轮旅客吞吐量一季度首次跻身中国前三
- 日本海岸漂浮大型鲸鱼尸体 长度达10至15米
- 封面有数丨2024五一假期出境游加速恢复,租车自驾成风潮
- 重提“归核战略”,麻醉药龙头还有机会吗?
- 北京车展观察:周鸿祎爬上车顶,BBA不再人满为患
- 周鸿祎:啥时候回国?贾跃亭:造车成功且还债之日!网友:错,是下周…
- 西班牙首相桑切斯在妻子遭受腐败指控后考虑辞职